物理日志和逻辑日志
日志一般分为逻辑日志与物理日志两类
「逻辑日志」:即执行过的事务中的sql语句,执行的sql语句(增删改)「反向」的信息
「物理日志」:mysql 数据最终是保存在数据页中的,物理日志记录的就是数据页变更
在Innodb存储引擎中,后台线程的主要作用是「负责刷新内存池中的数据,保证缓冲池中的内存缓存的是最近的数据」。此外它会将已经修改的数据文件刷新到磁盘文件中,保证在发生异常的情况下,Innodb能够恢复到正常的运行状态。
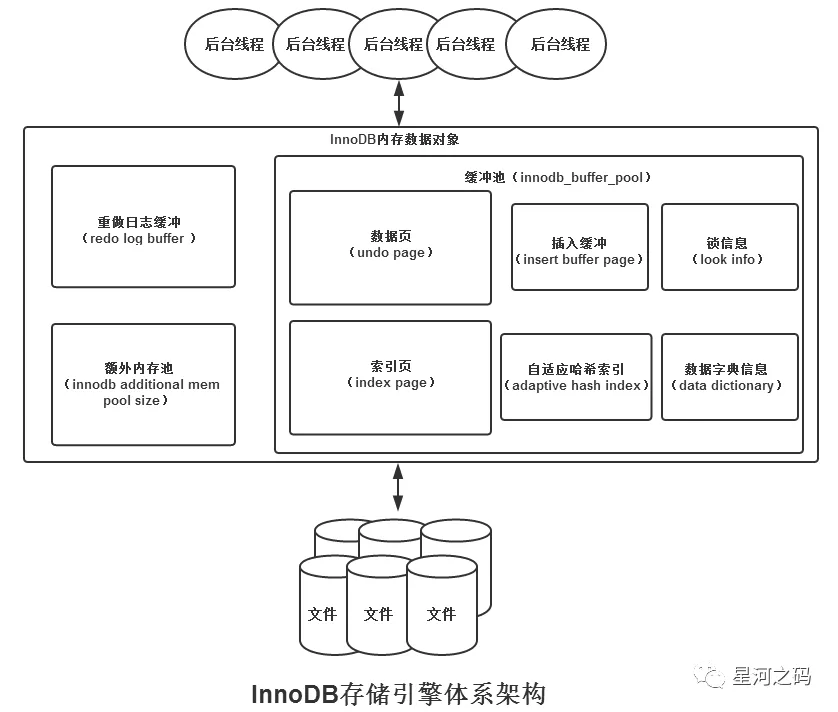
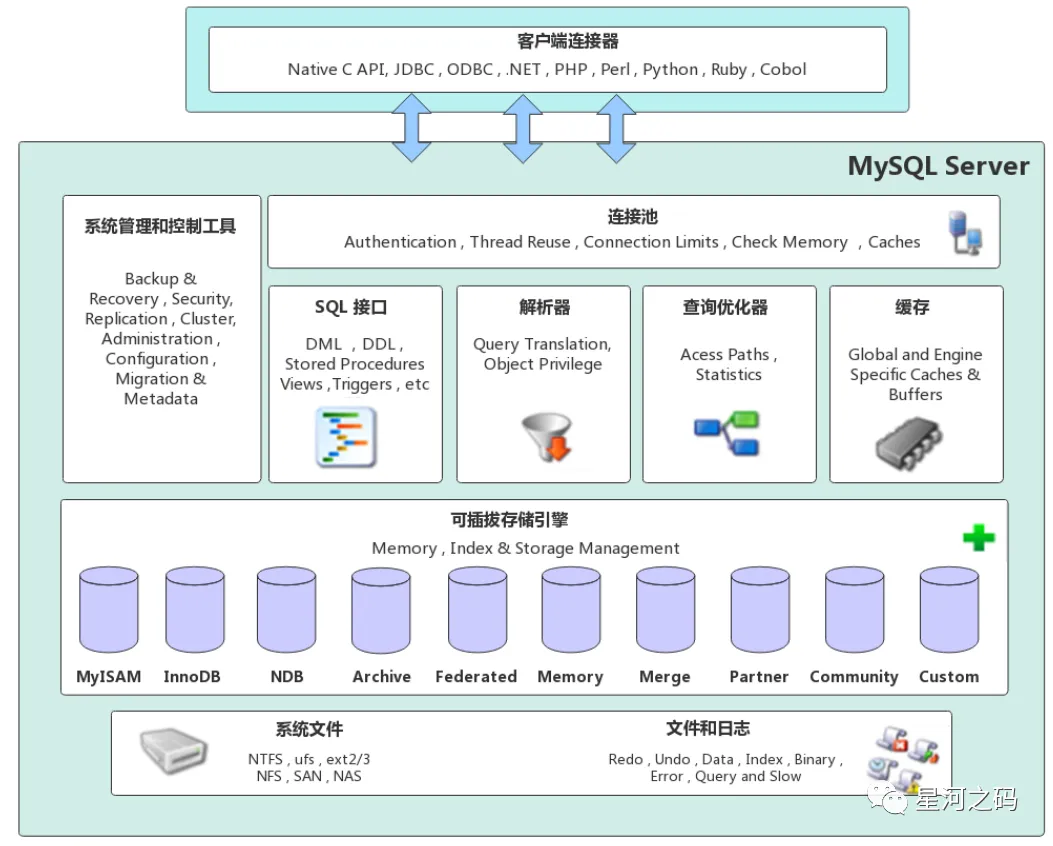
「MySQL存储引擎最大的特点就是【插件化】,可以根据自己的需求使用不同的存储引擎,innodb存储引擎支持行级锁以及事务特性,也是多种场合使用较多的存储引擎。」
当官方的存储引擎不足以满足时,我们通过抽象的API接口实现自己的存储引擎。
抽象存储引擎API接口是通过抽象类handler来实现,handler类提供诸如打开/关闭table、扫表、查询Key数据、写记录、删除记录等基础操作方法。
每一个存储引擎通过继承handler类,实现以上提到的方法,在方法里面实现对底层存储引擎的读写接口的转调。
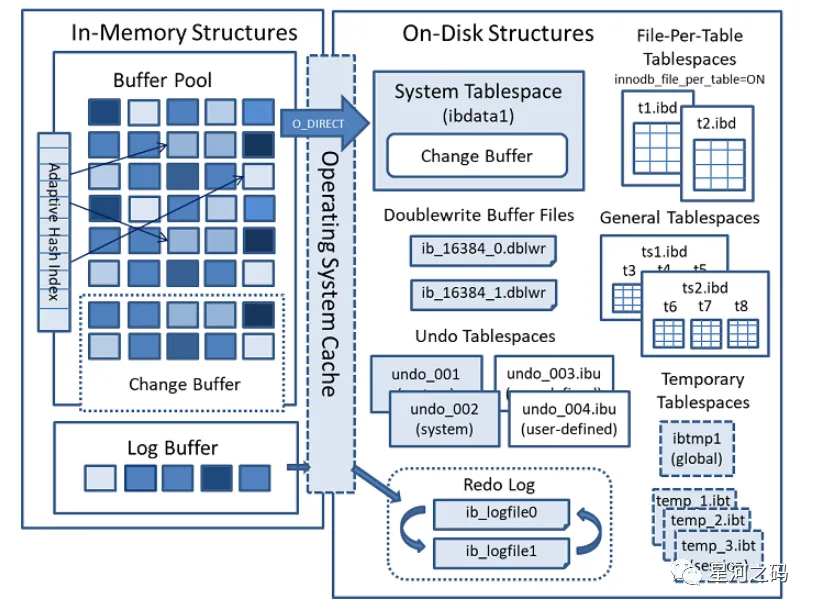
innodb数据逻辑存储形式为表空间,而每一个独立表空间都会有一个.ibd数据文件,ibd文件从大到小组成:
一个ibd数据文件–>Segment(段)–>Extent(区)–>Page(页)–>Row(行)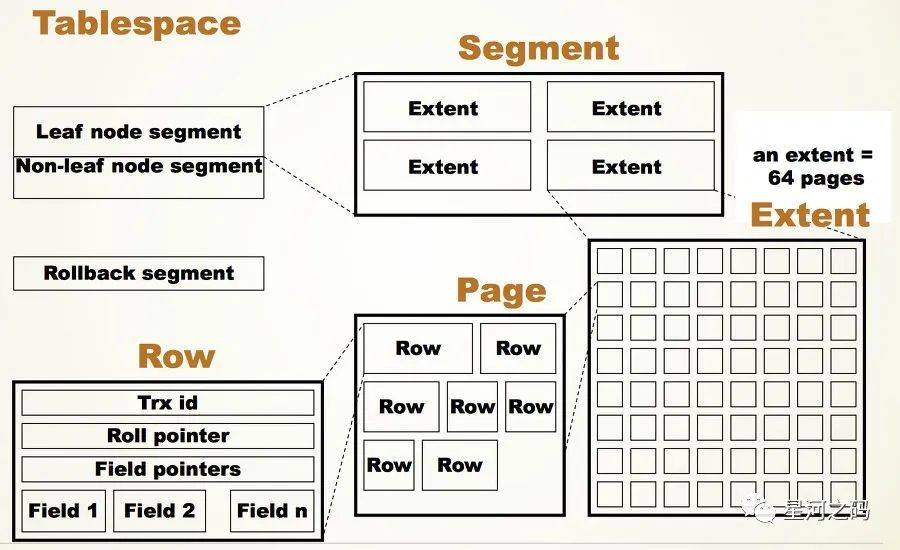
表空间,用于存储多个ibd数据文件,用于存储表的记录和索引,一个文件包含多个段。
段由数据段、索引段、回滚段组成,innodb存储引擎索引与数据共同存储,数据段即是B+树叶节点,索引段则存储非叶节点****。
区则是由连续页组成,每个区的大小为1M,一个区中一共有64个连续的页****。
页(Page)
页是innodb存储引擎磁盘管理的最小单位,页的大小为16KB,即每次数据的读取与写入都是以页为单位****。
包含很多种页类型,比如数据页,undo页,系统页,事务数据页,大的BLOB对象页
行包含记录的字段值,事务ID(Trx id)、滚动指针(Roll pointer)、字段指针(Field pointers)等信息。