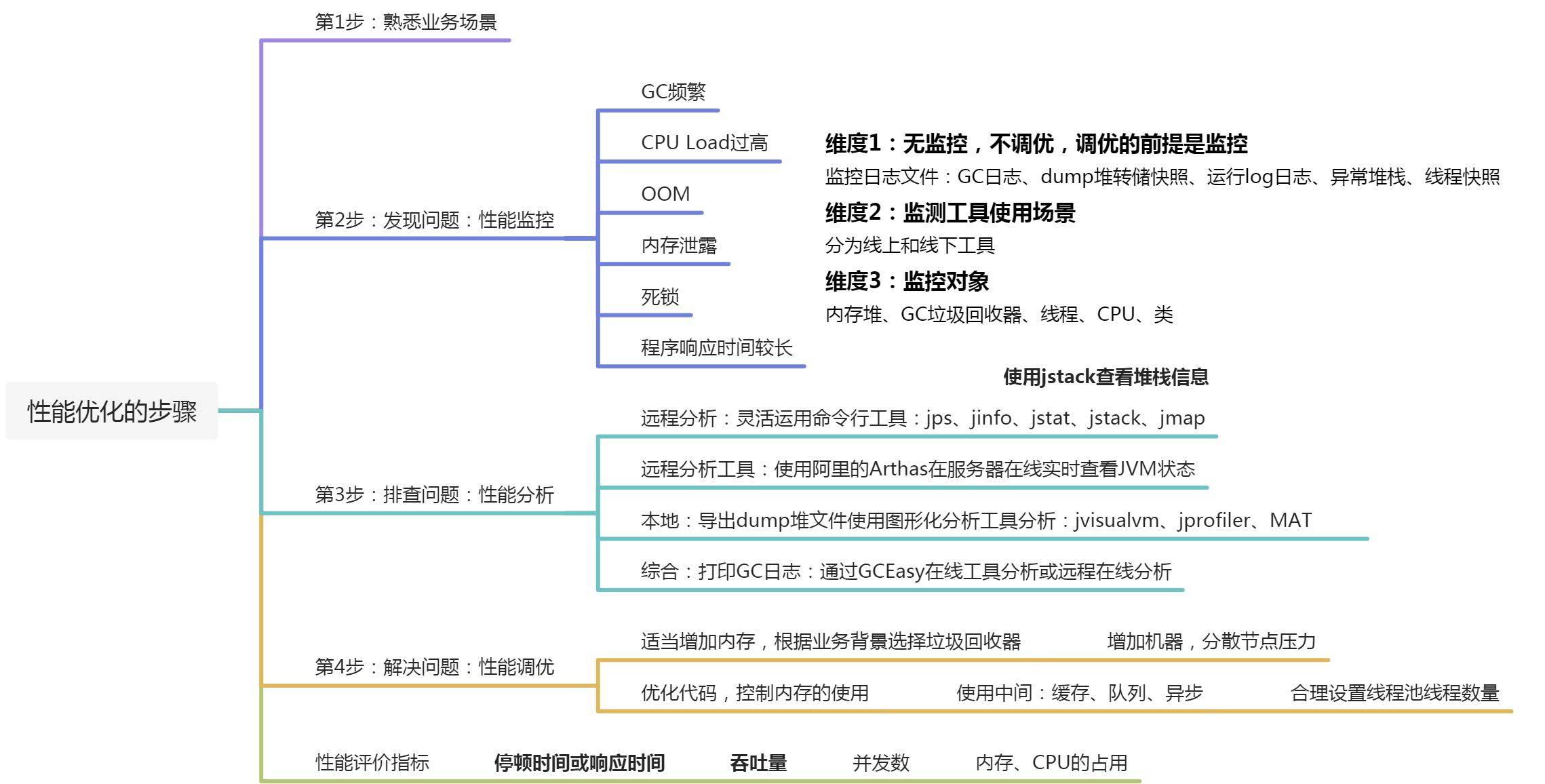
1 性能调优概述
2 OOM案例
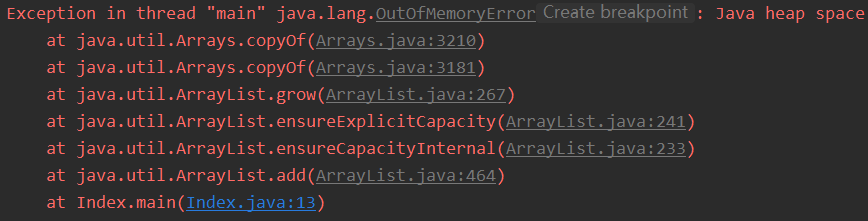
2.1 情况一:堆溢出(Java heap space)
代码与JVM参数设置
1 | ###1.0 代码 ### |
原因与解决方案
原因
- 代码中可能存在大对象分配
- 可能存在内存泄漏,导致在多次GC之后,还是无法找到一块足够大的内存容纳当前对象。** **
解决方案
- 检查是否存在大对象的分配,最有可能的是大数组分配
- 通过jmap命令,把堆内存dump下来,使用MAT等工具分析一下,检查是否存在内存泄漏的问题
- 如果没有找到明显的内存泄漏,使用 -Xmx 加大堆内存
- 还有一点容易被忽略,检查是否有大量的自定义的 Finalizable 对象,也有可能是框架内部提供的,考虑其存在的必要性
dump文件分析过程
JVisualVM分析
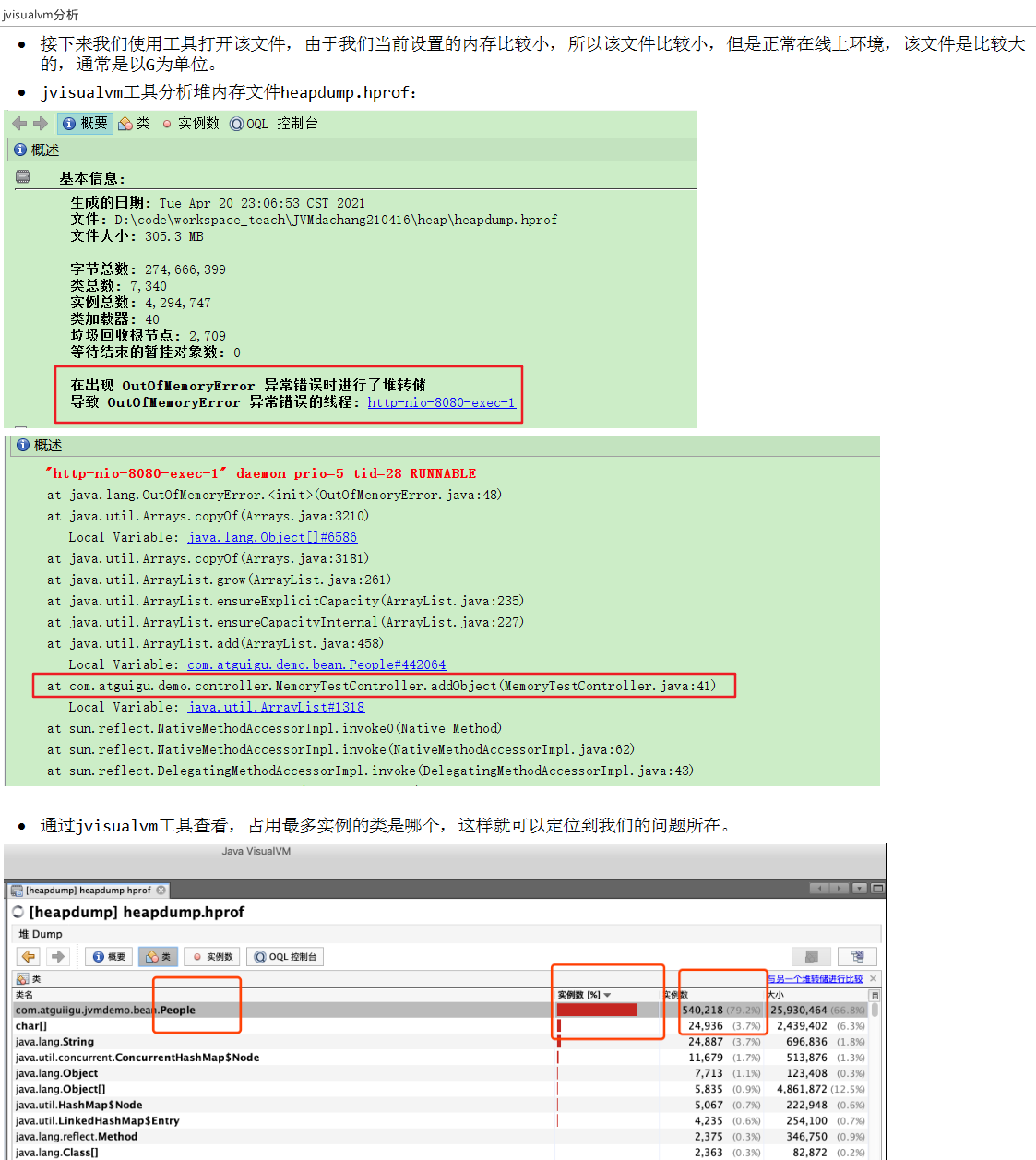
MAT分析
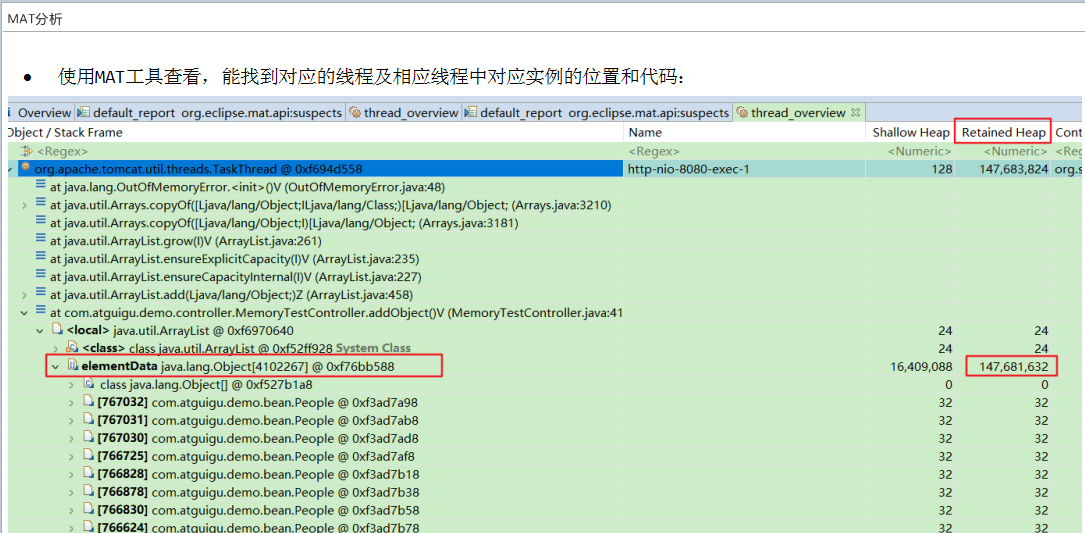
2.2 情况二:元空间溢出
代码与JVM参数设置
1 | ###1.0 ### |

原因与解决方案
原因
- 运行期间生成了大量的代理类,导致方法区被撑爆,无法卸载
- 应用长时间运行,没有重启
- 元空间内存设置过小
解决方案
- 检查是否永久代空间或者元空间设置的过小
- 检查代码中是否存在大量的反射操作
- dump之后通过mat检查是否存在大量由于反射生成的代理类并进行对应的代码优化
每次是不是可以只加载一个代理类即可,因为我们的需求其实是没有必要如此加载的,所以如上的代码可以这样改:
enhancer.setUseCache(true);选择为true的话,使用和更新一类具有相同属性生成的类的静态缓存(即使用缓存),而不会在同一个类文件还继续被动态加载并视为不同的类,这个其实跟类的equals()和hashCode()有关,它们是与cglib内部的class cache的key相关的
详细的分析步骤
查看监控
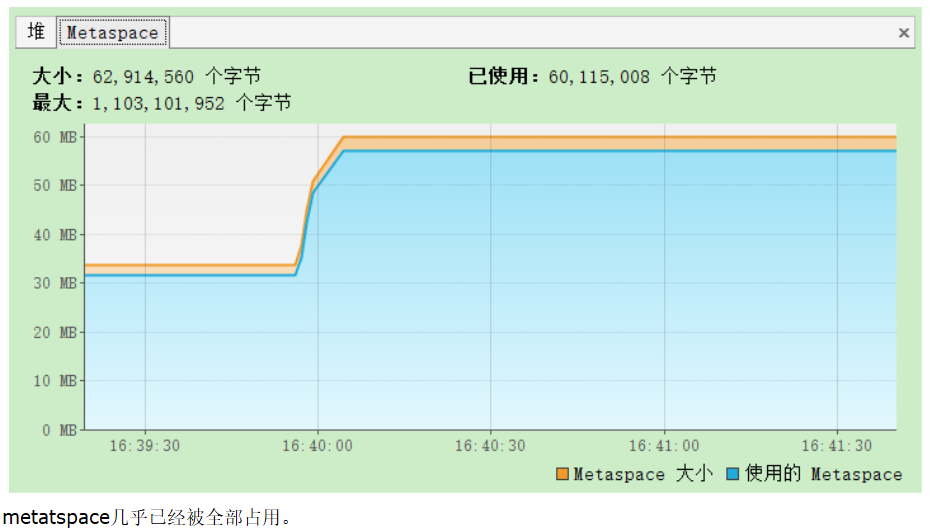
查看GC状态

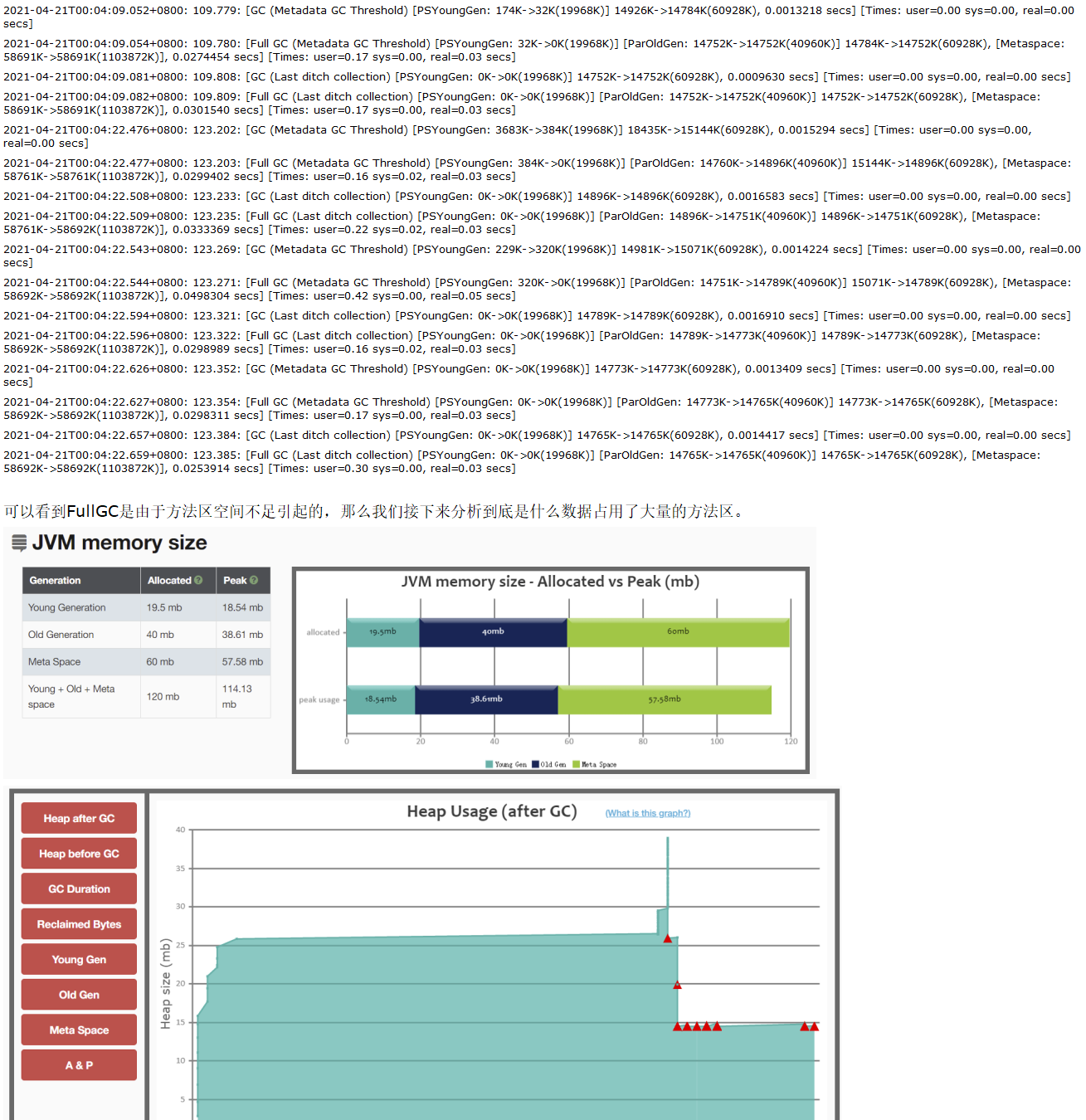
查看GC日志
分析dump文件
JVisualVM分析
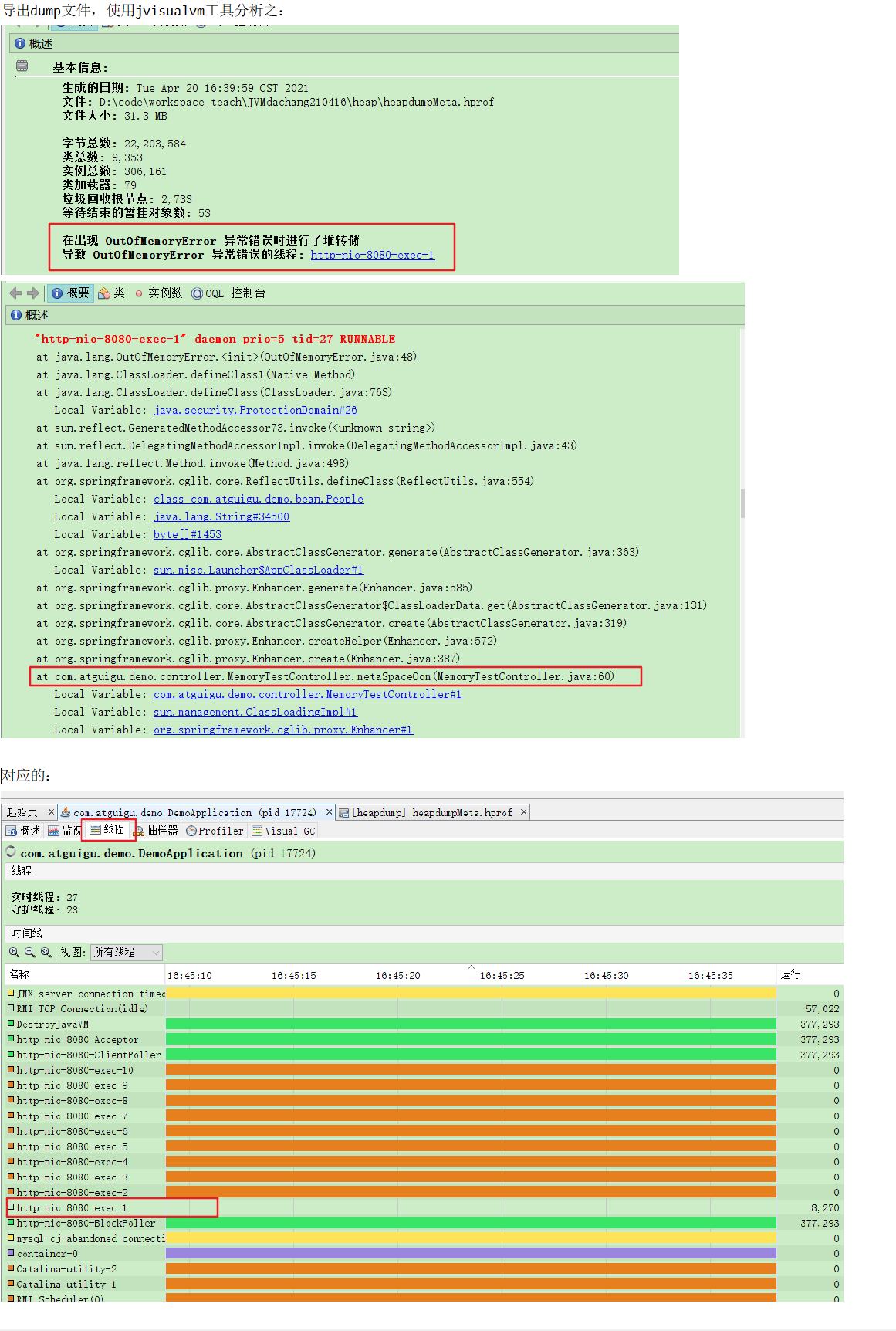
MAT分析
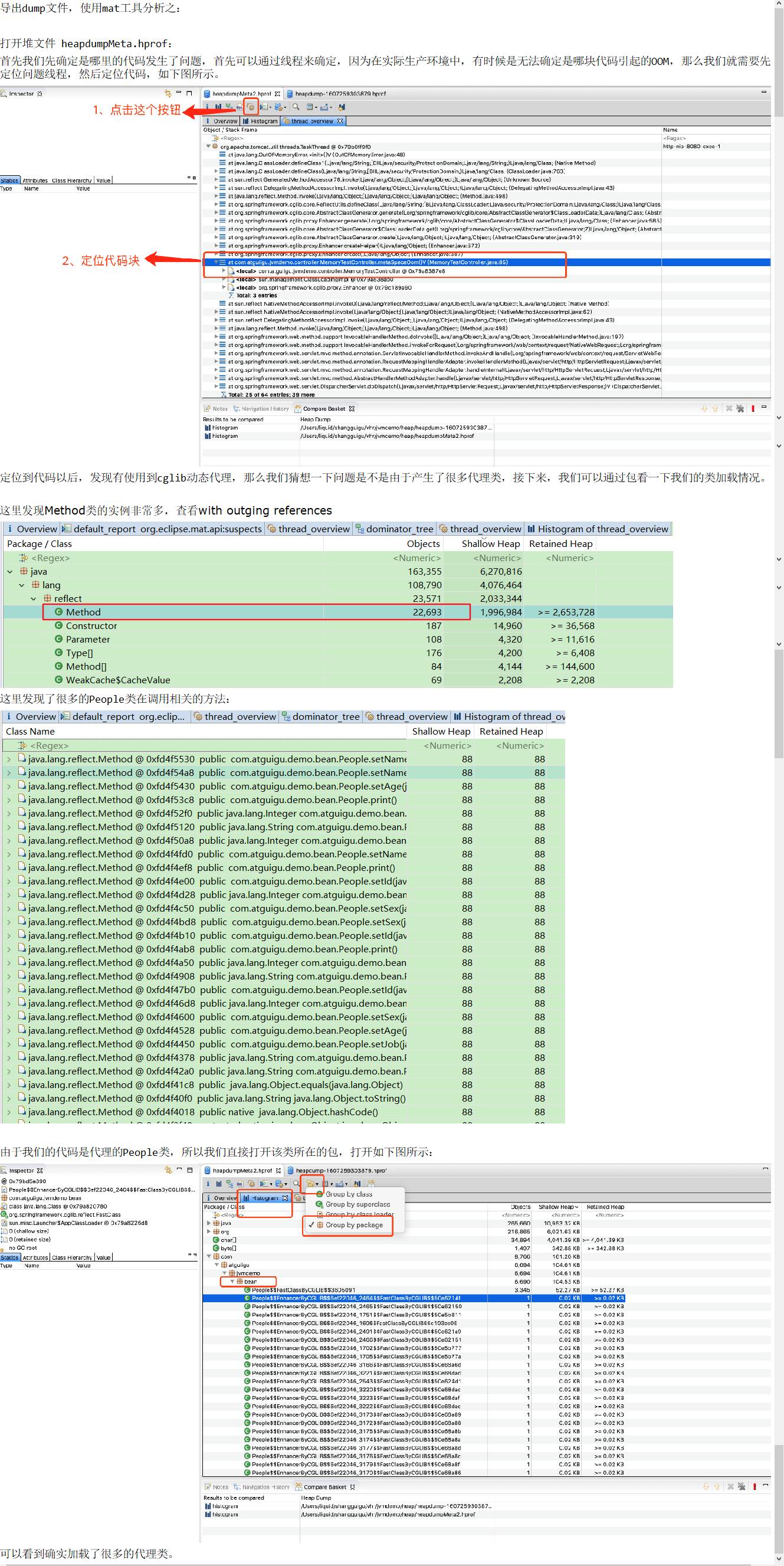
2.3 情况三:GC overhead limit exceeded
代码与JVM参数设置
1 | ###1.0 代码 ### |
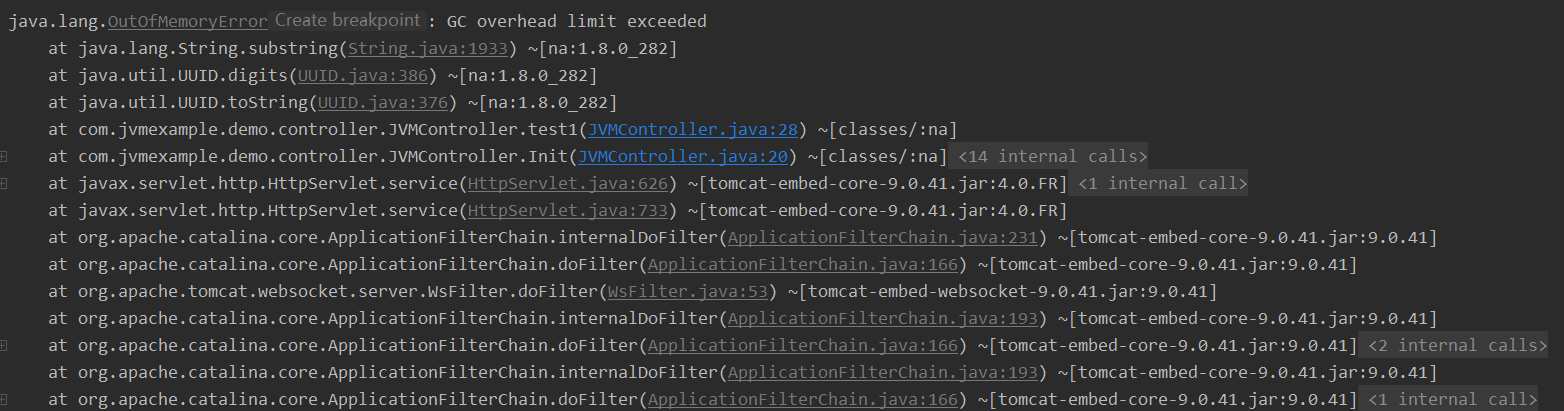
原因及解决方案分析
原因
这个是JDK6新加的错误类型,一般都是堆太小导致的。Sun 官方对此的定义:超过98%的时间用来做GC并且回收了不到2%的堆内存时会抛出此异常。本质是一个预判性的异常,抛出该异常时系统没有真正的内存溢出。
解决方案
- 检查项目中是否有大量的死循环或有使用大内存的代码,优化代码。
- 添加参数
-XX:-UseGCOverheadLimit禁用这个检查,其实这个参数解决不了内存问题,只是把错误的信息延后,最终出现 java.lang.OutOfMemoryError: Java heap space。 - dump内存,检查是否存在内存泄漏,如果没有,加大内存。
详细的分析步骤
定位问题代码
JVisualVM分析
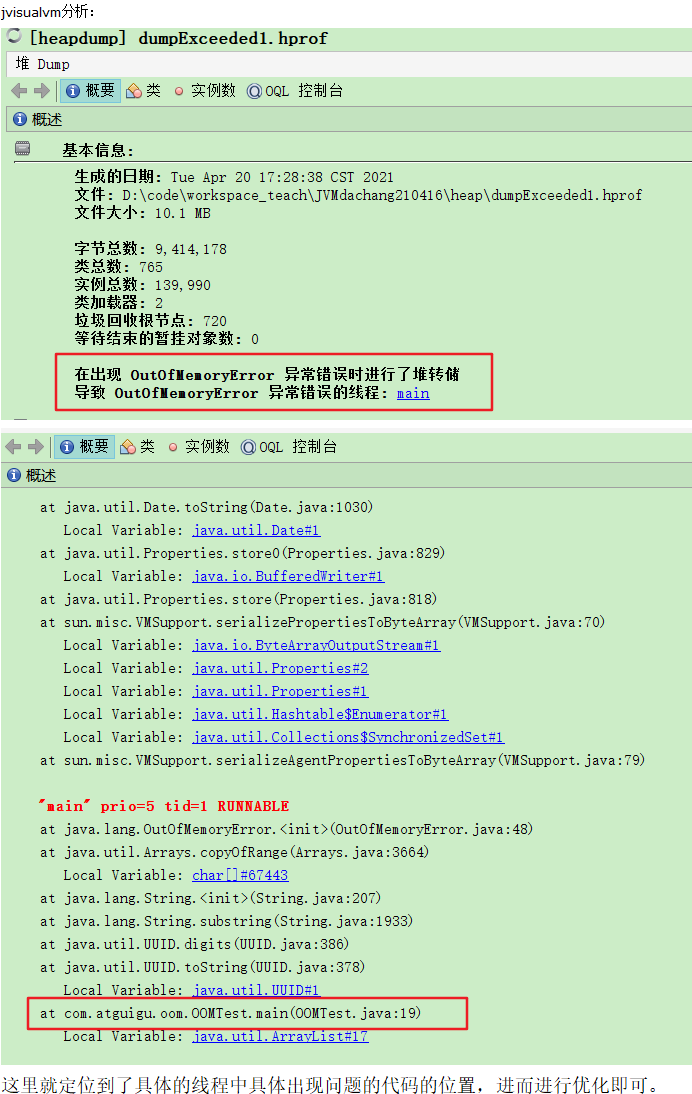
MAT分析
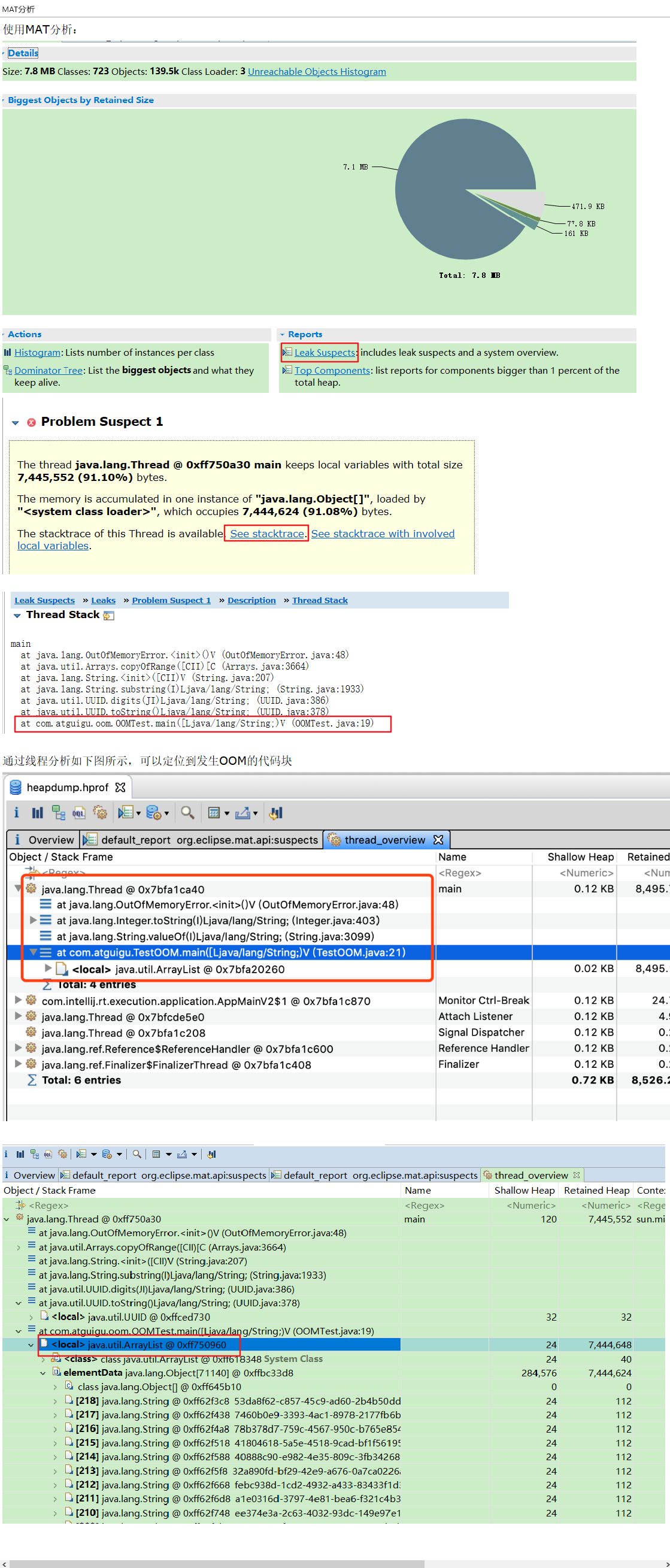
分析dump文件直方图
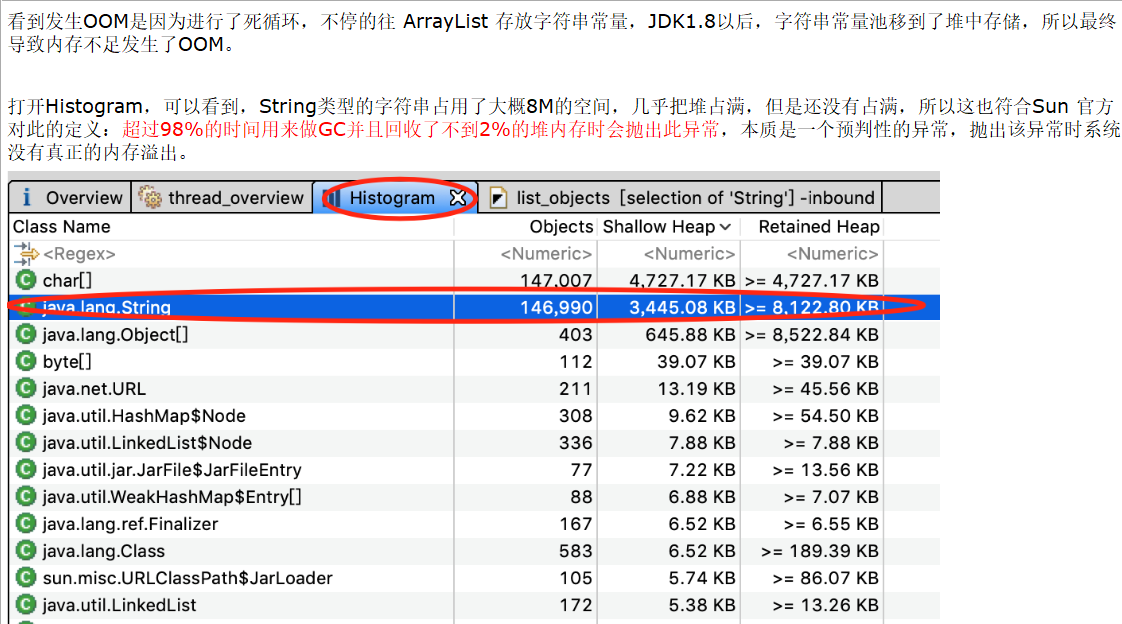
2.4 情况四:线程溢出
代码与错误描述
1 | ###1.0 参数设置 ### |

解决方案
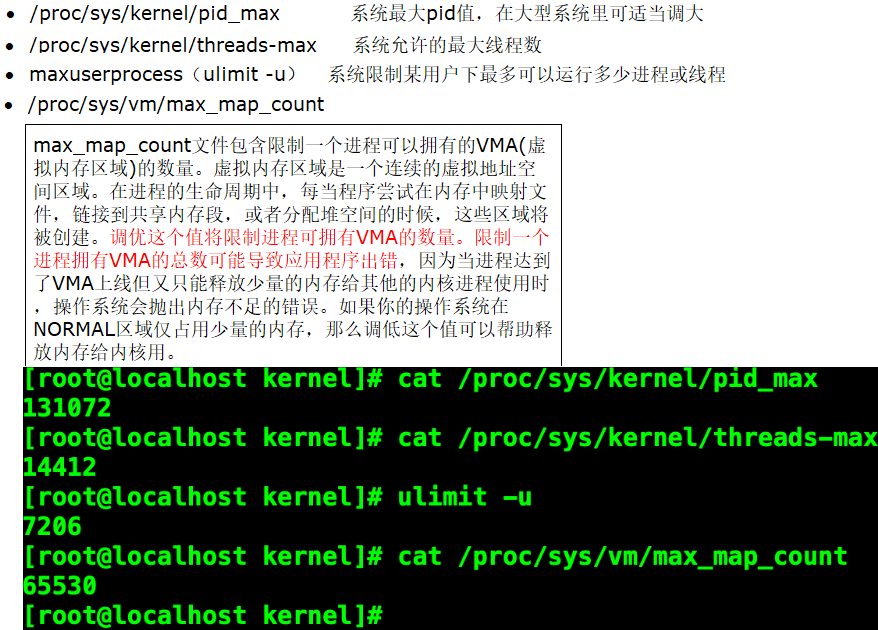
通过 -Xss 设置每个线程栈大小的容量

在生产环境下如果需要更多的线程数量,建议使用64位操作系统,如果必须使用32位操作系统,可以通过调整Xss的大小来控制线程数量。
线程总数也受到系统空闲内存和操作系统的限制,检查是否该系统下有此限制
3 性能优化案例
3.1 内存:合理分配堆内存
3.1.1 官方推荐配置
为什么要设置一个折中的堆内存空间?
如果内存过大,那么如果产生FullGC的时候,GC时间会相对比较长,如果内存较小,那么就会频繁的触发GC。
官方推荐配置
Java整个堆大小设置,Xmx 和 Xms设置为老年代存活对象的3-4倍,即FullGC之后的老年代内存占用的3-4倍。
年轻代Xmn的设置为老年代存活对象的1-1.5倍。
老年代的内存大小设置为老年代存活对象的2-3倍。
- 方法区(永久代 PermSize和MaxPermSize或元空间 MetaspaceSize 和 MaxMetaspaceSize)设置为老年代存活对象的1.2-1.5倍。
但是,上面的说法也不是绝对的,也就是说这给的是一个参考值,根据多种调优之后得出的一个结论,大家可以根据这个值来设置一下我们的初始化内存,在保证程序正常运行的情况下,我们还要去查看GC的回收率,GC停顿耗时,内存里的实际数据来判断,Full GC是基本上不能有的,如果有就要做内存Dump分析,然后再去做一个合理的内存分配。
3.1.2 如何计算老年代存活对象
方式一(推荐):查看GC日志
JVM参数中添加GC日志,GC日志中会记录每次FullGC之后各代的内存大小,观察老年代GC之后的空间大小。可观察一段时间内(比如2天)的FullGC之后的内存情况,根据多次的FullGC之后的老年代的空间大小数据来预估FullGC之后老年代的存活对象大小(可根据多次FullGC之后的内存大小取平均值)。
参考配置
1 | export CATALINA_OPTS="$CATALINA_OPTS -XX:+UseParallelGC" |
方式二:强制触发GC
注:强制触发FullGC,会造成线上服务停顿(STW),要谨慎!建议的操作方式为:在强制FullGC前先把服务节点摘除,FullGC之后再将服务挂回可用节点,对外提供服务,在不同时间段触发FullGC,根据多次FullGC之后的老年代内存情况来预估FullGC之后的老年代存活对象大小。
如何强制触发GC
服务器环境下
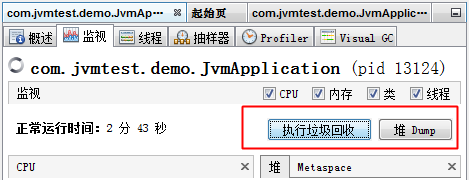
jmap -dump:live,format=b,file=heap.bin <pid>将当前的存活对象dump到文件。此时会触发FullGCjmap -histo:live <pid>打印每个class的实例数目,内存占用,类全名信息.live子参数加上后,只统计活的对象数量。此时会触发FullGC- 在测试环境,可以通过Java监控工具来触发FullGC,比如使用VisualVM和JConsole,VisualVM集成了JConsole,VisualVM或者JConsole上面有一个触发GC的按钮。
注:点击执行垃圾回收和堆dump按钮都会触发FullGC
触发了GC后如何查看老年代大小
- 使用
jmap -heap pid查看大小

- 使用
jstat -gc pid查看

- 直接查看GC日志

- 调整看下效果
配置案例
1 | -XX:+PrintGCDetails |
3.1.3 案例:调整堆空间大小后的优化效果
tomcat优化前的配置信息
说明:生产环境下,Tomcat并不建议直接在catalina.sh里配置变量,而是写在与catalina同级目录(bin目录)下的setenv.sh里。setenv.sh文件中写入(大小根据自己情况修改):setenv.sh内容如下:
1 | ###1.0 堆空间大小### |
分析过程:查看日志
- 通过
jps和jstat -gc pid 1000 10综合查看 - 通过
-Xloggc:/opt/tomcat8.5/logs/gc.log导出命令查看日志 - 通过JVisualVM进行查看
优化后的配置
1 | ### 核心:增加初始化和最大内存 ### |
效果:可明显感知到,增大了初始化内存和最大内存之后,FullGC的次数有一个明显的减少。
3.3 内存:新生代和老年代的比例设置说明(UseAdaptiveSizePolicy|SurvivorRatio)
背景:使用默认的SurvivorRatio不生效
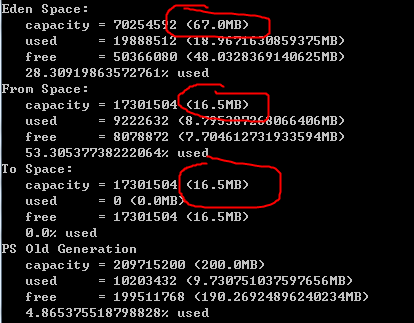
已知-XX:SurvivorRatio默认值为8,我们设置虚拟机为如下参数-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xms300M -Xmx300M -Xloggc:log/gc.log,通过查看jmap -heap pid发现,Eden和Survior并非是8:1:1的关系?
原因与实际推荐用法
1、这是因为JDK 1.8 默认使用 UseParallelGC 垃圾回收器,该垃圾回收器默认启动了 AdaptiveSizePolicy,会根据GC的情况自动计算计算 Eden、From 和 To 区的大小;所以这是由于JDK1.8的自适应大小策略导致的,除此之外,我们下面观察GC日志发现有很多类似这样的FULLGC(Ergonomics),也是一样的原因。
开启-XX:+UseAdaptiveSizePolicy关闭: -XX:-UseAdaptiveSizePolicy
2、在 JDK 1.8 中,如果使用 CMS,无论 UseAdaptiveSizePolicy 如何设置,都会将 UseAdaptiveSizePolicy 设置为 false;不过不同版本的JDK存在差异;
实际推荐用法
1、由于UseAdaptiveSizePolicy会动态调整 Eden、Survivor 的大小,有些情况存在Survivor 被自动调为很小,比如十几MB甚至几MB的可能,这个时候YGC回收掉 Eden区后,还存活的对象进入Survivor 装不下,就会直接晋升到老年代,导致老年代占用空间逐渐增加,从而触发FULL GC,如果一次FULL GC的耗时很长(比如到达几百毫秒),那么在要求高响应的系统就是不可取的。
结论1:UseAdaptiveSizePolicy不要和SurvivorRatio参数显示设置搭配使用,一起使用会导致UseAdaptiveSizePolicy参数失效,即SurvivorRatio如果不启用,其就不会是默认的值8,如果启用了,其优先级高于UseAdaptiveSizePolicy
结论2:对于面向外部的大流量、低延迟系统,不建议启用此参数,建议关闭该参数。即:<font style="background-color:#FADB14;">XX:-UseAdaptiveSizePolicy</font>
2、如果不想动态调整内存大小,还有另外一个方法:保持使用 UseParallelGC,显式设置 -XX:SurvivorRatio=8,其也会达到关闭自动调整的目的
需要注意的一点是:如果垃圾回收器使用的就是ParallelGC ,只要没有手动配置过 -XX:SurvivorRatio=8,即使这时候手动配置了-XX:-UseAdaptiveSizePolicy,那也不会按照8:1:1。同时只要手动配置了
-XX:SurvivorRatio=8,即使这时候又配置了-XX:+UseAdaptiveSizePolicy,那也是按照-XX:SurvivorRatio=8优先生效。
配置-XX:+PrintGCDateStamps -Xms300M -Xmx300M -XX:SurvivorRatio=4其效果就是严格按照Eden和From、To区4:1:1分配的。
3.3 内存飙高分析
系统内存飙高,如何查找问题?(面试高频)
- 使用线上分析工具:jmap -heap查看堆情况 、jstat统计gc与类的信息、jinfo查看参数配置属性、第三方的分析工具Arthas
- 使用线下分析工具:JVisualVM,MAT
- 查看dump文件:导出堆存储dump分析,查看线程、类之间的关系
- 查看GC文件:查看GC日志文件,FullGC次数等。
- 角度:从堆的角度、GC垃圾回收器的角度。
3.4 CPU飙高分析
3.4.1 概述
系统CPU经常100%,如何调优?(面试高频)
CPU100%的话,一定是有线程占用系统资源。需要注意的是:工作中有时候是工作线程100%占用了CPU,还有可能是垃圾回收线程占用了100%。
3.4.2 演示代码
1 | //死锁产生类 |
3.4.3 本地JVisualVM分析
在执行的过程中,已经发现了CPU忽然骤升,提示检测到死锁此时通过查看线程->生成线程dump文件进行分析

3.4.4 服务器远程在线分析
步骤一:ps aux得到进程pid(得到具体进程)
已知CPU忽然骤升了,此时要得到具体是哪个进程出了问题
方式一:显示CPU消耗排名前20的进程,索引为2的为CPU,为3的为内存占比
ps -aux | sort -k3,3nr | head -20
方式二:使用ps命令分析占比最高的CPU,排查下具体是哪个进程,Windows可直接使用任务管理器。查看到当前java进程使用cpu、内存、磁盘的情况获取使用量异常的进程。
ps aux | grep java
方式三:Java应用,也可直接使用jps -l得到具体的进程ID
jps -l
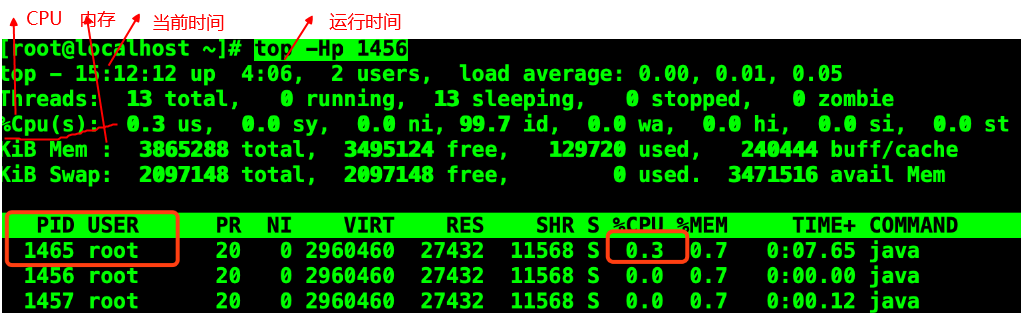
步骤二:top -Hp pid得到该进程下的异常线程nid(得到具体线程)
备注:top命令可实时显示 process 的动态。shift+p 按cpu排序,shift+m 按内存排序
由图可知,当前占用cpu比较高的线程 ID 是1465
1 | 扩展:top的使用 |
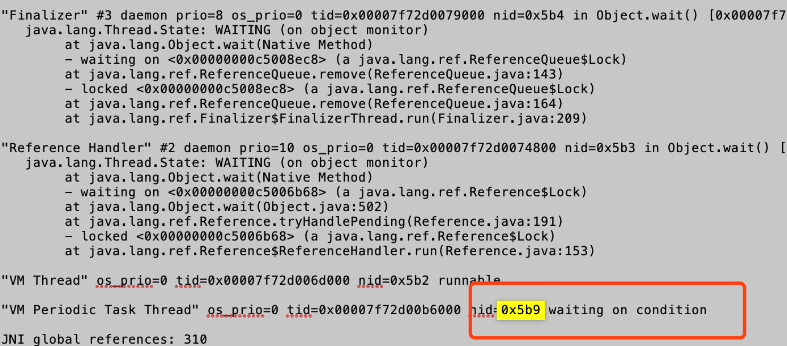
步骤三:jstack pid | grep -A20 tid排查具体日志信息(根据进程和线程得到具体日志)
方式一:使用jstack pid | grep -A20 十六进制线程tid在线排查
先将上面得到的线程tid1456转成十六进制0x5b9,使用jstack pid | grep -A20 0x5b9其中-A20是显示20条代码,能看到具体的nid=0x5b9的线程信息
方式二:将文件输出到当前目录下并命名为jstack.log,导出本地搜索

3.5 垃圾回收器:根据业务场景选择合适的垃圾回收器
如何选择合适的垃圾回收器?
Java 垃圾收集器的配置对于 JVM 优化来说是一个很重要的选择,选择合适的垃圾收集器可以让 JVM 的性能有一个很大的提升。
怎么选择垃圾收集器?
- 优先调整堆的大小让 JVM 自适应完成。
- 如果内存小于 100M,使用串行收集器
- 如果是单核、单机程序,并且没有停顿时间的要求,串行收集器
- 如果是多 CPU、需要高吞吐量、允许停顿时间超过 1 秒,选择并行或者 JVM 自己选择
- 如果是多 CPU、追求低停顿时间,需快速响应(比如延迟不能超过 1 秒,如互联网应用),使用并发收集器
官方推荐 G1,性能高。现在互联网的项目,基本都是使用 G1。
| 组合 | 垃圾收集器 | 分类 | 作用位置 | 使用算法 | 特点 | 适用场景 | 历史 |
|---|---|---|---|---|---|---|---|
| 可组合 |
Serial | 串行运行 | 作用于新生代 | 复制算法 | 响应速度优先 | 适用于单 CPU 环境下的 client 模式 | JDK1.3 之前回收新生代唯一的选择。 Serial 收集器作为 HotSpot 中 client 模式下的默认新生代垃圾收集器 |
| Serial Old | 串行运行 | 作用于老年代 | 标记-压缩算法 | 响应速度优先 | 适用于单 CPU 环境下的 Client 模式 | ||
| ParNew | 并行运行 | 作用于新生代 | 复制算法 | 响应速度优先 | 多 CPU 环境 Server 模式下与 CMS 配合使用 | ||
| CMS | 并发运行 | 作用于老年代 | 标记-清除算法 | 响应速度优先 | 适用于互联网或 B/S 业务 | JDK14 发布。删除 CMS 垃圾回收器 | |
| 可组合 | Parallel | 并行运行 | 作用于新生代 | 复制算法 | 吞吐量优先 | 适用于后台运算而不需要太多交互的场景 | Parallel GC 在 JDK6 之后成为 HotSpot 默认 GC JDK8默认组合就是使用Parallel GC+Parallel Old GC |
| Parallel Old | 并行运行 | 作用于老年代 | 标记-压缩算法 | 吞吐量优先 | 适用于后台运算而不需要太多交互的场景 | ||
| 全功能独立 | G1 | 并发、并行运行 | 作用于新生代、老年代 | 标记-压缩算法、复制算法 | 响应速度优先 | 面向服务端应用 | JDK7开始引入 JDK9 中 G1 变成默认的垃圾收集器,以替代 CMS |
GC 发展阶段:Serial => Parallel(并行)=> CMS(并发)=> G1 => ZGC
最后需要明确一个观点:
- 没有最好的收集器,更没有万能的收集
- 调优永远是针对特定场景、特定需求,不存在一劳永逸的收集器
G1垃圾回收器推荐使用
年轻代大小
- 避免使用
-Xmn或-XX:NewRatio等相关选项显式设置年轻代大小 - 固定年轻代的大小会覆盖暂停时间目标
暂停时间目标不要太过严苛
- G1 GC 的吞吐量目标是 90%的应用程序时间和 10%的垃圾回收时间
- 评估 G1 GC 的吞吐量时,暂停时间目标不要太严苛。目标太过严苛表示你愿意承受更多的垃圾回收开销,而这些会直接影响到吞吐量。
G1并发执行的线程对性能的影响
使用指南:G1垃圾收集器的并发标记的线程属性-XX:ConcGCThreads值的设置对于性能具有一定的影响,相对而言,其值增加会使平均响应时间和GC时间都有一个明显的减少了,从而吞吐量将会增大。
使用G1作为垃圾回收器的JVM参考优化
1 | export CATALINA_OPTS="$CATALINA_OPTS -XX:+UseG1GC" |
辅助参考:G1的JVM参数设置
1 | -XX:+UseG1GC:手动指定使用 G1 垃圾收集器执行内存回收任务 |
3.6 JIT的优化
说明:不对JIT进行优化不影响,因为默认开启了标量替换
详见堆文档下面的内容:https://www.yuque.com/zhuyufei-x9kmd/npm5bq/gd8hmk/edit#igic3堆是分配对象的唯一选择么?
堆,是分配对象的唯一选择吗?
阶段一:是
JVM虚拟机对象就是分配在堆上的。尤其是JDK方法区从永久代变更为了元空间,intern字符串缓存和静态变量并不是被转移到元数据区,而是直接在堆上分配上,可以说吗堆就是分配对象的唯一选择。
阶段二:不是
在《深入理解Java虚拟机中》关于Java堆内存有这样一段描述:随着JIT编译期的发展与逃逸分析技术逐渐成熟,栈上分配、标量替换优化技术将会导致一些微妙的变化,所有的对象都分配到堆上也渐渐变得不那么“绝对”了。在Java虚拟机中,对象是在Java堆中分配内存的,这是一个普遍的常识。但是,有一种特殊情况,那就是如果经过逃逸分析(Escape Analysis)后发现,一个对象并没有逃逸出方法的话,那么就可能被优化成栈上分配。这样就无需在堆上分配内存,也无须进行垃圾回收了。这也是最常见的堆外存储技术。此外,前面提到的基于OpenJDK深度定制的TaoBaoVM,其中创新的GCIH(GC invisible heap)技术实现off-heap,将生命周期较长的Java对象从heap中移至heap外,并且GC不能管理GCIH内部的Java对象,以此达到降低GC的回收频率和提升GC的回收效率的目的。
阶段三:是
JVM 会在栈上分配那些不会逃逸的对象,这在理论上是可行的,但是取决于 JVM 设计者的选择。而Oracle Hotspot JVM 中并未实现逃逸分析,所以从HotSpot JVM的角度可以明确说:所有的对象实例都是创建在堆上(性能优化来自于标量替换)。
JIT的性能开销
时间开销
解释器的执行,抽象的看是这样的:
输入的代码 -> [ 解释器 解释执行 ] -> 执行结果
JIT编译然后再执行的话,抽象的看则是:
输入的代码 -> [ 编译器 编译 ] -> 编译后的代码 -> [ 执行 ] -> 执行结果
说明:说JIT比解释快,其实说的是“执行编译后的代码”比“解释器解释执行”要快,并不是说“编译”这个动作比“解释”这个动作快。JIT编译再怎么快,至少也比解释执行一次略慢一些,而要得到最后的执行结果还得再经过一个“执行编译后的代码”的过程。所以,对“只执行一次”的代码而言,解释执行其实总是比JIT编译执行要快。
怎么算是只执行一次的代码呢?粗略说,下面条件同时满足时就是严格的`只执行一次。
- 只被调用一次,例如类的构造器(class initializer,())
- 没有循环,对只执行一次的代码做JIT编译再执行,可以说是得不偿失。
- 对只执行少量次数的代码,JIT编译带来的执行速度的提升也未必能抵消掉最初编译带来的开销。
备注:只有对频繁执行的代码(热点代码),JIT编译才能保证有正面的收益。
空间开销
对一般的Java方法而言,编译后代码的大小相对于字节码的大小,膨胀比达到10+是很正常的。同上面说的时间开销一样,这里的空间开销也是,只有对执行频繁的代码才值得编译,如果把所有代码都编译则会显著增加代码所占空间,导致代码爆炸。这也就解释了为什么有些JVM会选择不总是做JIT编译,而是选择用解释器+JIT编译器的混合执行引擎。
JIT的参数配置
1 | -server -Xmx100m -Xms100m -XX:+DoEscapeAnalysis -XX:+PrintGC -XX:+EliminateAllocations |
这里设置参数如下:
- 参数
-server:启动 Server 模式,因为在 server 模式下,才可以启用逃逸分析。 - 参数
-XX:+DoEscapeAnalysis:启用逃逸分析(默认打开)

- 参数
-Xmx10m:指定了堆空间最大为 10MB - 参数
-XX:+PrintGC:将打印 Gc 日志 - 参数
-XX:+EliminateAllocations:开启了标量替换(默认打开),允许将对象打散分配在栈上,比如对象拥有 id 和 name 两个字段,那么这两个字段将会被视为两个独立的局部变量进行分配
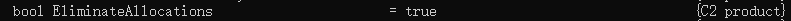
3.10 经典题
50万PV大堆案例
说明:有一个50万PV的资料类网站(从磁盘提取文档到内存)原服务器是32位的,1.5G的堆,用户反馈网站比较缓慢。因此公司决定升级,新的服务器为64位,16G的堆内存,结果用户反馈卡顿十分严重,反而比以前效率更低了!
Q1:为什么原网站慢?
频繁的GC,STW时间比较长,响应时间慢
Q2:为什么会更卡顿?
内存空间越大,出现了大堆,导致FGC时间更长,延迟时间更长
Q3:怎么处理?
使用并行的垃圾回收器:吞吐量parallel GC ; 低延迟G1
配置GC参数:-XX:MaxGCPauseMillis 、 -XX:ConcGCThreads
根据log日志、dump文件分析,优化内存空间的比例
jstat jinfo jstack jmap
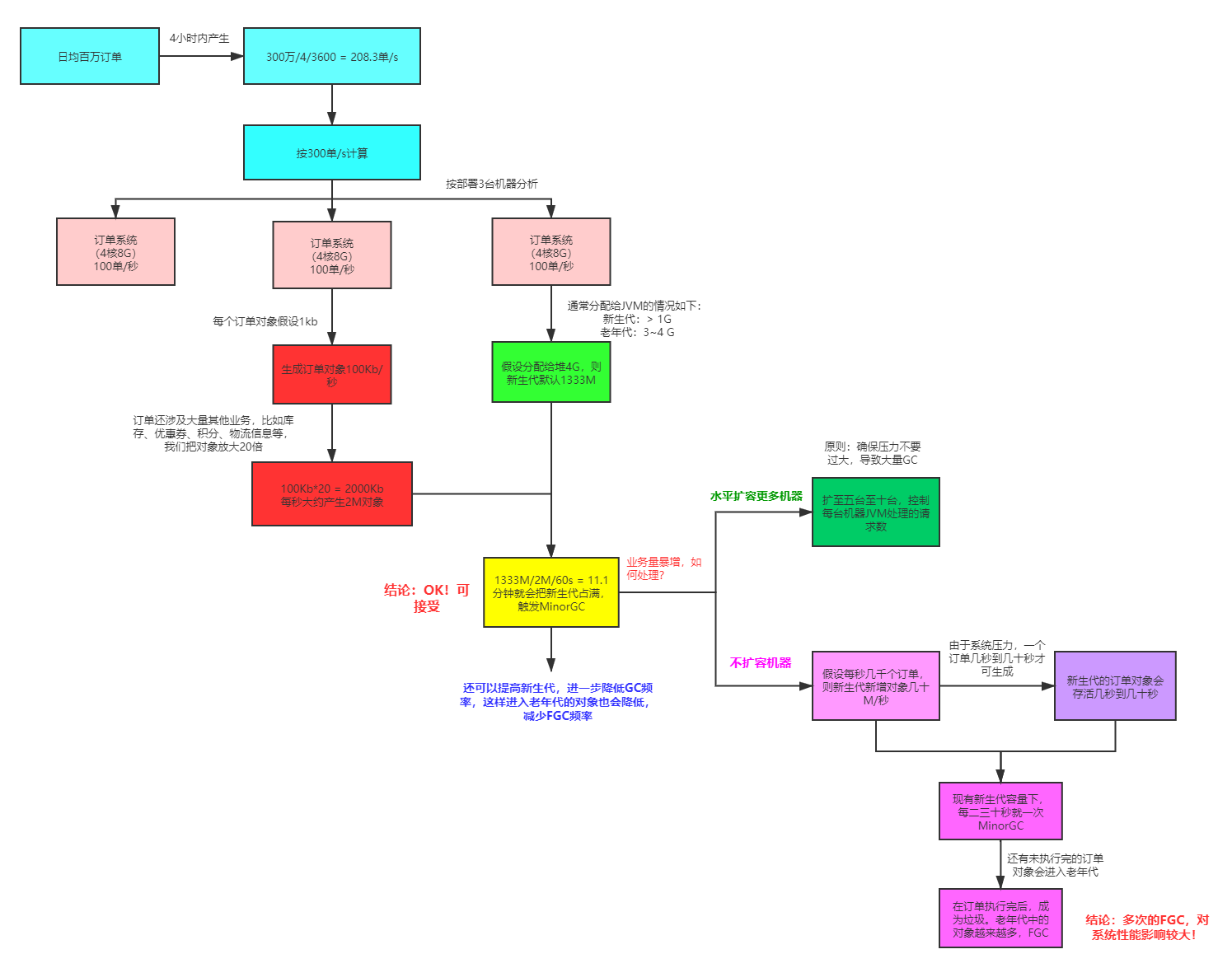
百万订单的jvm参数配置